【Java】Integer的自动拆包
文章主要讨论了在Java中Integer自动拆包的问题,并解答了关于hashCode和identityHashCode的区别,以及它们与Integer自动拆包之间的关系。文章通过源码分析,解释了Integer的自动拆包机制,并说明了为什么当两个Integer对象在-128到127的范围内时,它们是同一个对象,因此它们的hashCode和identityHashCode相同,而在范围外则是不同的对象,因此它们的hashCode和identityHashCode不同。文章还强调了基本数据类型int通过valueof方法自动拆包的过程,以及为什么这样设计可以提高性能。最后,作者指出这个问题很有价值,因为它迫使自己去Java的源码中寻找底层设计,并通过解读源码来解决问题。
关于Integer的自动拆包问题的思考
前言
发这篇博客的主要原因之一是,寒假实验室大作业的思考题就是这个,所有想写篇博客来专门分析并解答这个问题。下面就开始吧!
思考题原题
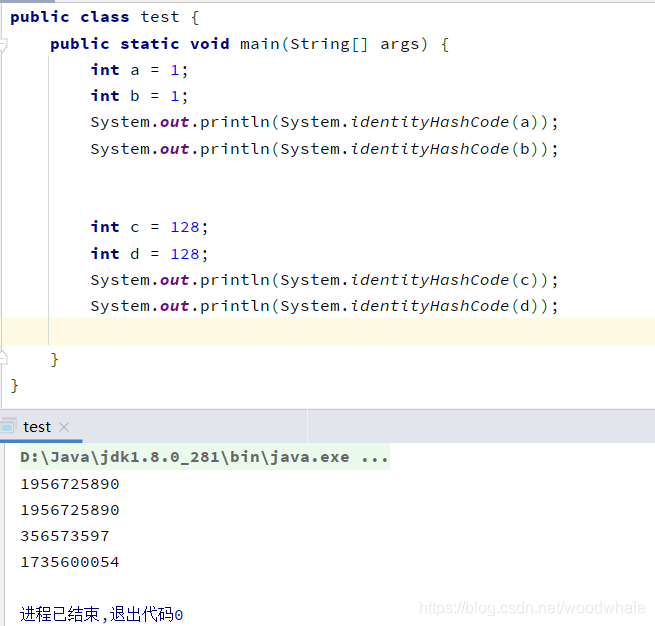
问题1:为什么hash值不同? 问题2:int i = 1 如果i作为如图的一个局部变量,底层到底发生了什么?建议画个图详细描述一下(请用自己的理解来说)
对题目的思考
已知信息: 1、显而易见,输出的前两个值,是相等的,而输出的后两个值,是不等的。 2、从数值层面,int型的 a 和 b 数值相等,int型的 c 和 d 数值相等。 3、从输出层面,输出的 identityHashCode(a) 和 identityHashCode(b) 相等,输出的 identityHashCode(c) 和 identityHashCode(d) 不相等。
未知信息: 1、输出的这些数值表示的是什么? 2、identityHashCode 与 HashCode 有什么区别? 3、 identityHashCode(a) 和 identityHashCode(b) 相等 而 identityHashCode(c) 和 identityHashCode(d) 不相等的原因是什么?
这些信息我们在下面我们一一分析,一一解答!
hashCode与identityHashCode
我们直接上hashCode的源码:
* <ul>
* <li>Whenever it is invoked on the same object more than once during
* an execution of a Java application, the {@code hashCode} method
* must consistently return the same integer, provided no information
* used in {@code equals} comparisons on the object is modified.
* This integer need not remain consistent from one execution of an
* application to another execution of the same application.
* <li>If two objects are equal according to the {@code equals(Object)}
* method, then calling the {@code hashCode} method on each of
* the two objects must produce the same integer result.
* <li>It is <em>not</em> required that if two objects are unequal
* according to the {@link java.lang.Object#equals(java.lang.Object)}
* method, then calling the {@code hashCode} method on each of the
* two objects must produce distinct integer results. However, the
* programmer should be aware that producing distinct integer results
* for unequal objects may improve the performance of hash tables.
* </ul>
public native int hashCode();
借助百度翻译,源码大概说的是这三点: 1、在一个java程序执行期间,同一个对象无论不管调用几次hashCode()方法,返后的都是同一个整形数。 2、如果一个对象调用equals()方法与另一个对象相等,则这两个对象调用hashCode()后返后值相同。 3、如果一个对象调用equals()方法与另一个对象不相等,则这两个对象调用hashCode()后返回值不同。
简而言之,hashCode方法可以判断是否为同一对象!
但是我再看了看源码,发现,String类重写了hashCode方法:
/** The value is used for character storage. */
private final char value[];
/** Cache the hash code for the string */
private int hash; // Default to 0
/**
* Returns a hash code for this string. The hash code for a
* <code>String</code> object is computed as
* <blockquote><pre>
* s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
* </pre></blockquote>
* using <code>int</code> arithmetic, where <code>s[i]</code> is the
* <i>i</i>th character of the string, <code>n</code> is the length of
* the string, and <code>^</code> indicates exponentiation.
* (The hash value of the empty string is zero.)
*
* @return a hash code value for this object.
*/
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
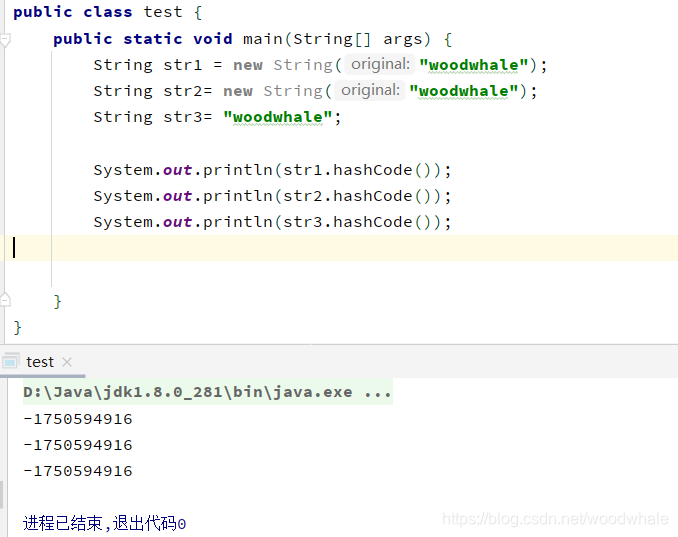
直接说结论:重写后的hashCode方法不再是以equals方法的返回值为参考了,而是返回一个表达式计算的值,只要String里的值相同,返回的hash码值就相同。 举个例子:
String str1 = new String("woodwhale");
String str2= new String("woodwhale");
String str3= "woodwhale";
System.out.println(str1.hashCode());
System.out.println(str2.hashCode());
System.out.println(str3.hashCode());
说了这么多hashCode,那么identityHashCode和hashCode的区别呢?
我们来看看identityHashCode的源码:
/**
* Returns the same hash code for the given object as
* would be returned by the default method hashCode(),
* whether or not the given object's class overrides
* hashCode().
* The hash code for the null reference is zero.
*
* @param x object for which the hashCode is to be calculated
* @return the hashCode
* @since JDK1.1
*/
public static native int identityHashCode(Object x);
通俗的来讲,调用identityHashCode方法,不管调用的对象它所在的类有没有对hashCode重写,都直接执行Object类中的hashCode方法! 举一样的例子:
public class test {
public static void main(String[] args) {
String str1 = new String("woodwhale");
String str2= new String("woodwhale");
String str3= "woodwhale";
String str4=str3;
System.out.println(System.identityHashCode(str1));
System.out.println(System.identityHashCode(str2));
System.out.println(System.identityHashCode(str3));
System.out.println(System.identityHashCode(str4));
}
}
结果是下图: 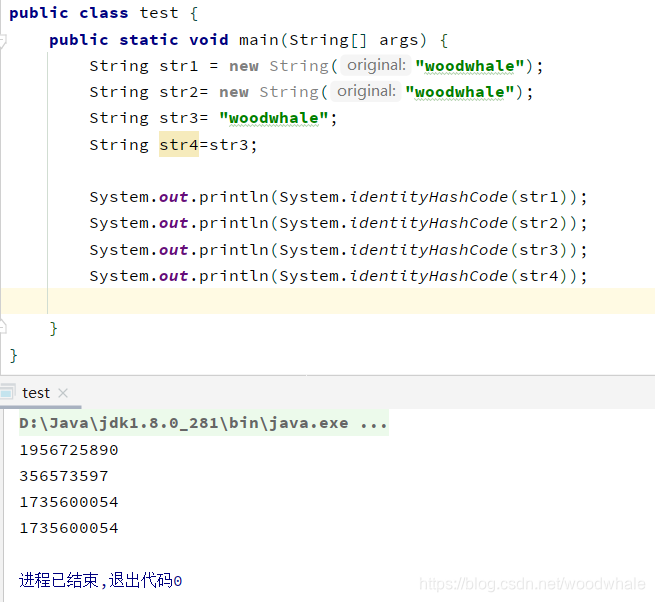 所以 hashCode 与 identityHashCode 的区别就是:hashCode会被重写,identityHashCode不会被重写,直接调用object类的hashCode方法。
所以 hashCode 与 identityHashCode 的区别就是:hashCode会被重写,identityHashCode不会被重写,直接调用object类的hashCode方法。
那么hashCode与identityHashCode的区别就这么多,解决了identityHashCode问题之后,我们就来解决,为啥返回值不同的问题,接下来我们就引入Integer自动拆包的问题。
Integer的自动拆包
先看一段测试代码:
public class test {
public static void main(String[] args) {
int a = 128, b = 128;
System.out.println("run result NO.1->"+(a == b));
Integer c = 128, d = 128;
System.out.println("run result NO.2->"+(c == d));
Integer e = 100, f = 100;
System.out.println("run result NO.3->"+(e == f));
}
}

在Java中,如果是基本数据类型,则 == 比较的是值;如果是对象类型,则 == 比较的是对象的地址。测试NO.1为true,因为int是基本数据类型,仅仅比较值。而测试NO.2和3都是Integer对象类型,为何返回值不一样呢?
这个时候我们就引入自动拆装箱机制:
百度百科中关于自动拆装箱的解释: Java拆装箱就是Java相应的基本数据类型和引用类型的互相转化
如 Integer a = 1; 其中 a为Integer类型,而1为int类型,且Integer与int之间并没有继承关系,按照java一般情况处理运行程序会报异常。但是因为自动拆装箱的存在,在为Integer类型的变量赋int类型的值时,Java会自动将int类型的转换为Integer类型。 即 Integer a = Integer.valueOf(1);
涉及到自动拆装箱机制,看看Integer.valueOf()的源码是怎么实现的:
/**
* Returns an {@code Integer} instance representing the specified
* {@code int} value. If a new {@code Integer} instance is not
* required, this method should generally be used in preference to
* the constructor {@link #Integer(int)}, as this method is likely
* to yield significantly better space and time performance by
* caching frequently requested values.
*
* This method will always cache values in the range -128 to 127,
* inclusive, and may cache other values outside of this range.
*
* @param i an {@code int} value.
* @return an {@code Integer} instance representing {@code i}.
* @since 1.5
*/
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
注释中说到参数i如果在-128~127之间,那么返回值就是从缓存中取出并返回的,反之就通过new Integer(i)的方式返回。源码中的IntegerCache是这样写的:
/**
* Cache to support the object identity semantics of autoboxing for values between
* -128 and 127 (inclusive) as required by JLS.
*
* The cache is initialized on first usage. The size of the cache
* may be controlled by the {@code -XX:AutoBoxCacheMax=<size>} option.
* During VM initialization, java.lang.Integer.IntegerCache.high property
* may be set and saved in the private system properties in the
* sun.misc.VM class.
*/
private static class IntegerCache {
static final int low = -128;
static final int high;
static final Integer cache[];
static {
// high value may be configured by property
int h = 127;
String integerCacheHighPropValue =
sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
if (integerCacheHighPropValue != null) {
try {
int i = parseInt(integerCacheHighPropValue);
i = Math.max(i, 127);
// Maximum array size is Integer.MAX_VALUE
h = Math.min(i, Integer.MAX_VALUE - (-low) -1);
} catch( NumberFormatException nfe) {
// If the property cannot be parsed into an int, ignore it.
}
}
high = h;
cache = new Integer[(high - low) + 1];
int j = low;
for(int k = 0; k < cache.length; k++)
cache[k] = new Integer(j++);
// range [-128, 127] must be interned (JLS7 5.1.7)
assert IntegerCache.high >= 127;
}
private IntegerCache() {}
}
通过源码和注释传递的信息我们清晰的得到,在其static块初始化时就一次性生成了-128到127直接的Integer类型变量存储在cache[]中,对于-128到127之间的int类型,返回的都是同一个Integer类型对象。
为什么这样设计呢?其实Integer.valueOf()的注释方法中就说明了这个原因:
As this method is likely to yield significantly better space and time performance by caching frequently requested values. 因为通过缓存频繁请求的值,此方法可能会产生显著更好的空间和时间性能。
所以,当自动装箱int型值在-128到127之间时,即直接返回IntegerCache中暂存的Integer类型对象。而在这个范围之外,则会新建一个Integer对象(在源码里是cache)。
信息结合解决问题
我们将得到的信息结合起来:
1、identityHashCode 是直接用object类的hashCode方法来判断两个对象是否相同,不存在重写问题。 2、Integer的缓存值是**-128~127**,在这个范围内值相等是同一个对象,在范围外就是new了新对象(cache) 3、基本数据类型int通过valueof方法自动拆包
综合以上信息,我们可以得出为什么 题目中输出的 identityHashCode(a) 和 identityHashCode(b) 相等,输出的 identityHashCode(c ) 和 identityHashCode(d) 不相等。因为a,b在-128~127的范围内,valueof方法转化为Integer类之后,是同一个对象,所以返回的hash值相同,而c,d在范围之外,valueof方法转化类型之后,是重新new了对象,两个不同对象,返回的hash值不同!
所以int a = 1,在底层运行的机制,首先进行valueof方法自动拆包,拆包时判断是否在 -128~127范围内,如果在,那么就直接 retuen new Integer(a),反之调用IntegerCache方法新new一个Integer对象!
后话
这道思考题我觉得很有价值,第一次让我去Java中看源码找底层设计,通过对源码的解读,终于是了解了这一题的奥妙!