【Python】正则表达式进阶
这篇文章提供了Python正则表达式的进阶内容,包括分组、先行断言、后行断言等高级概念,并提供了多个示例说明如何使用这些概念。分组用于捕获数据,并在匹配中选择每个分组。先行断言和后行断言则允许在特定位置进行正向或反向搜索,以确保匹配符合特定条件。此外,还介绍了非捕获分组和分组回溯引用的概念,以及如何提取特定模式的数据,如学号、日期、图片文件后缀名等。最后,文章提供了两个示例,用于提取所有人的生日和匹配所有小数,以巩固正则表达式的使用。
python正则表达式进阶
前言
在写学习完了正则表达式的入门内容之后,正则表达式的进阶内容今天也一并学习掉吧!
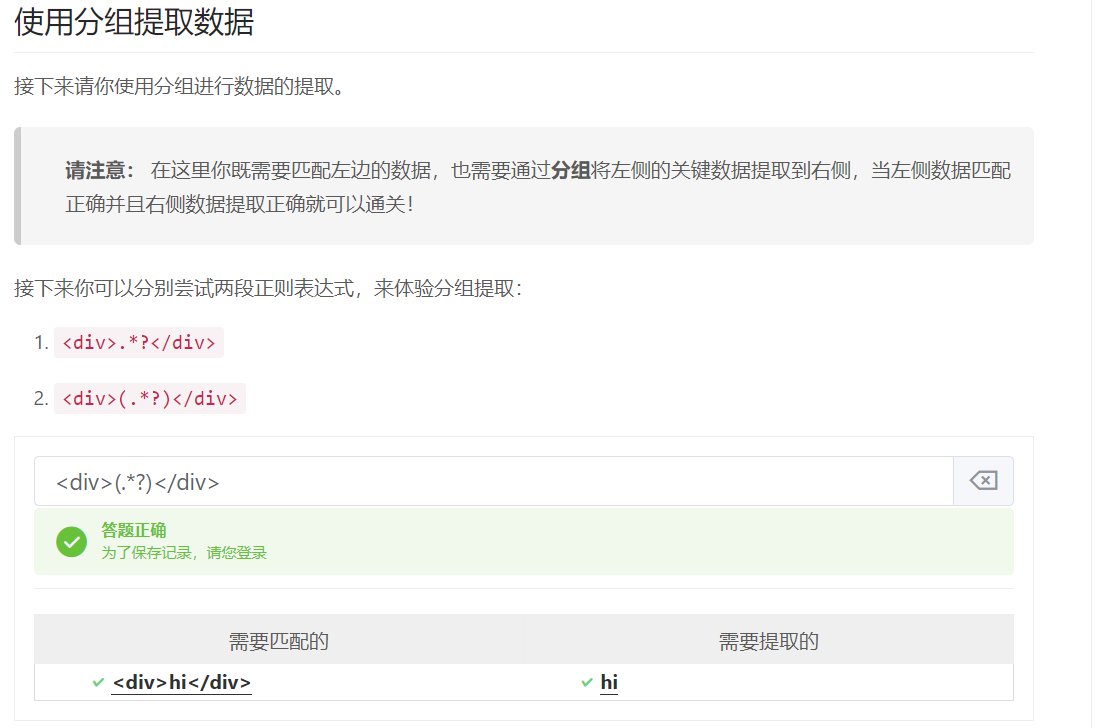
1、分组
1.分组
在正则表达式中还提供了一种将表达式分组的机制,当使用分组时,除了获得整个匹配。还能够在匹配中选择每一个分组。
要实现分组很简单,使用()即可。
分组有一个非常重要的功能——捕获数据。所以()被称为捕获分组,用来捕获数据,当我们想要从匹配好的数据中提取关键数据的时候可以使用分组。
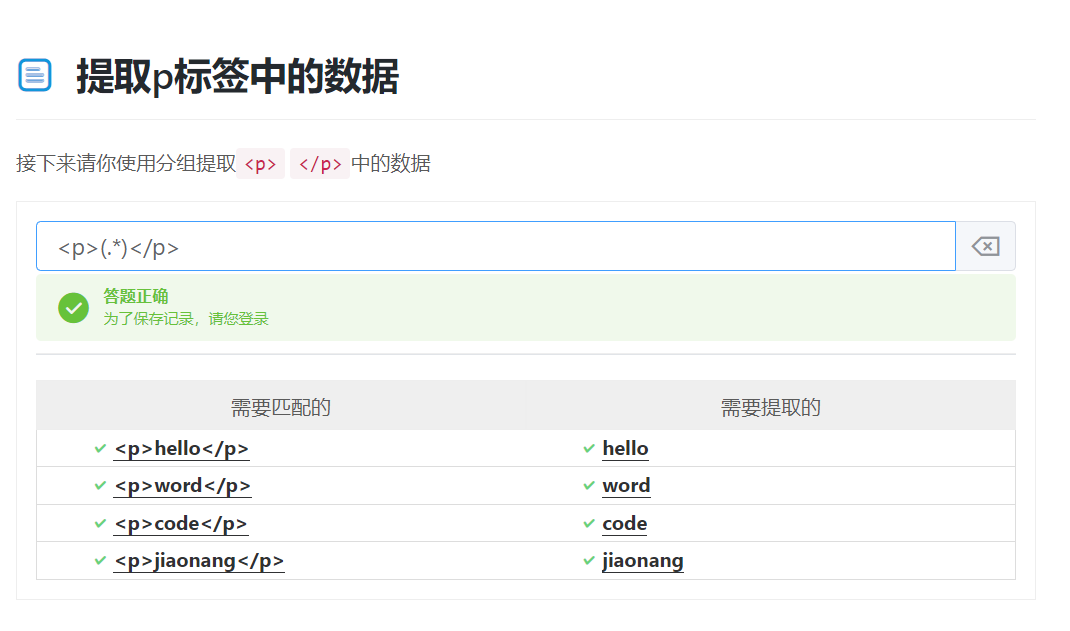
2.提取p标签中的数据
<p>(.*)</p>
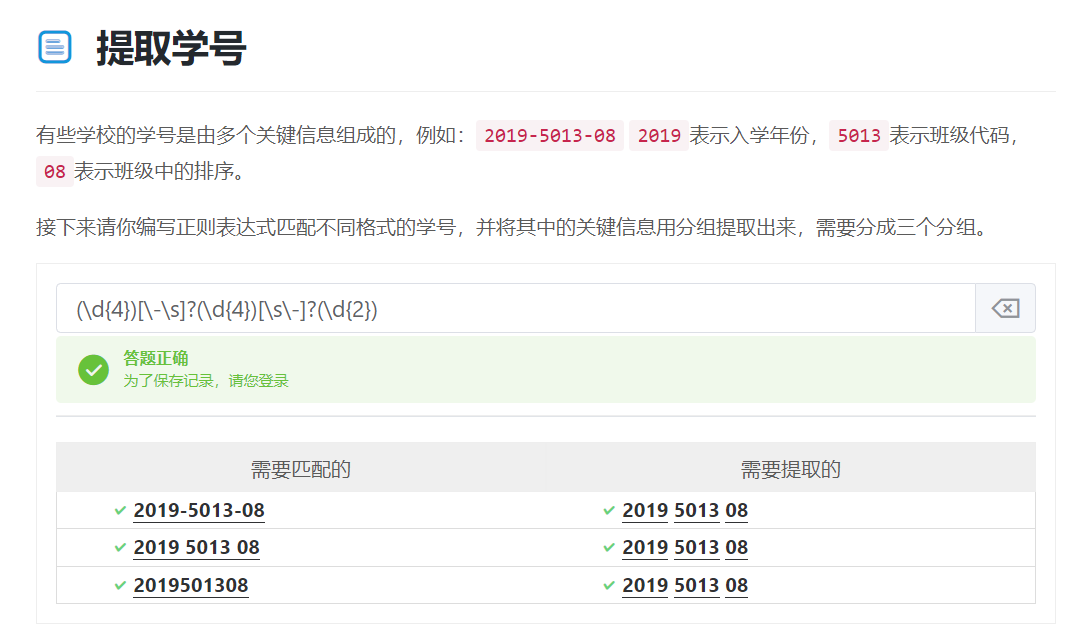
3.提取学号
(\d{4})[-\s]?(\d{4})[\s-]?(\d{2})
4.提取年月日
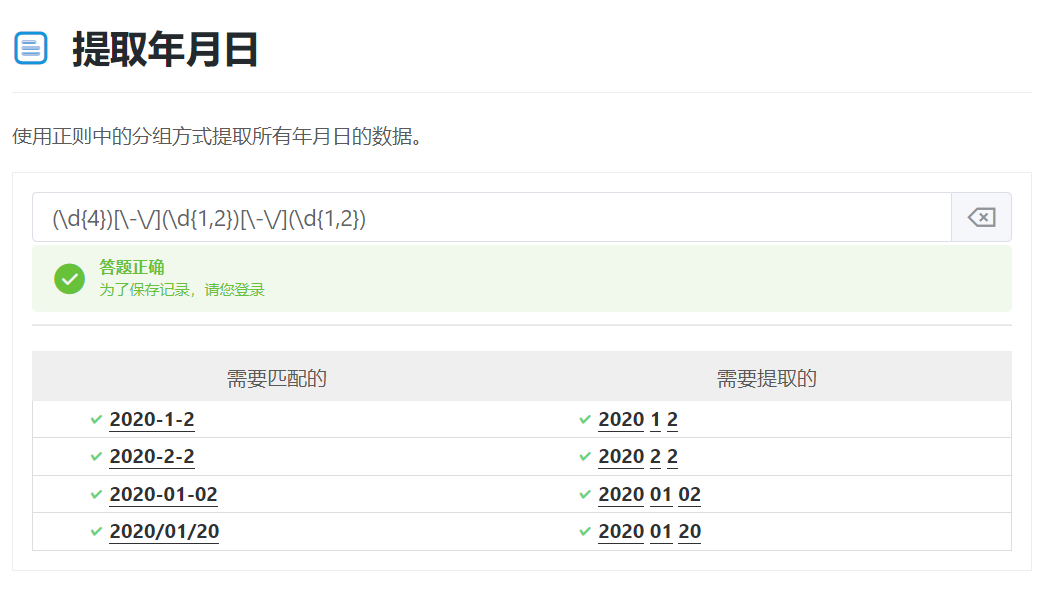
5.或者条件
使用分组的同时还可以使用 或者(or)条件。
例如要提取所有图片文件的后缀名,可以在各个后缀名之间加上一个 |符号:
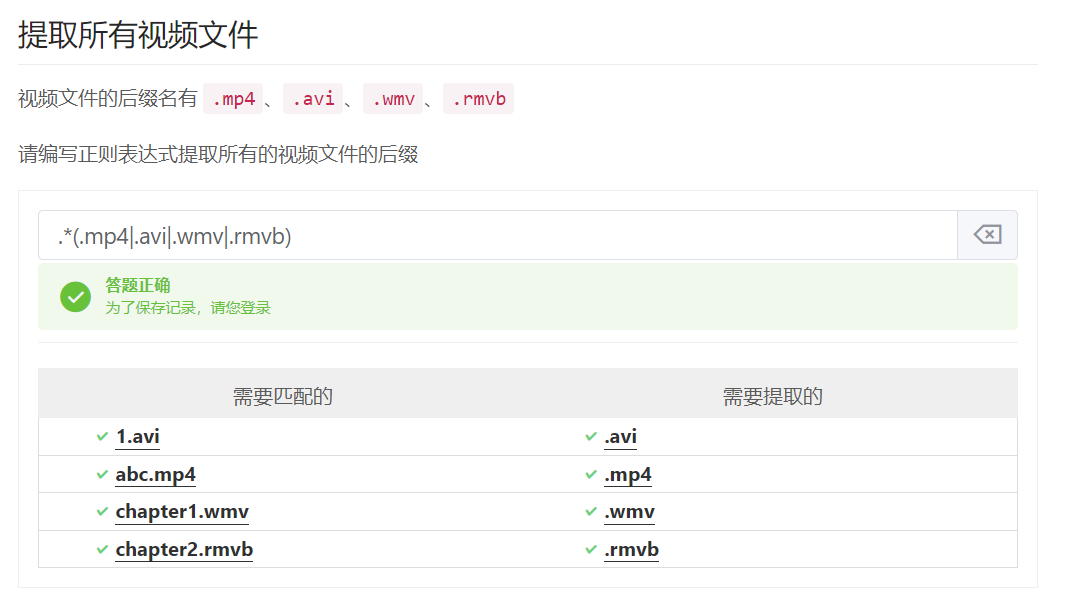
6.非捕获分组
有时候,我们并不需要捕获某个分组的内容,但是又想使用分组的特性。
这个时候就可以使用非捕获组(?:表达式),从而不捕获数据,还能使用分组的功能。
(?:\d*-|tel:)(\d*)
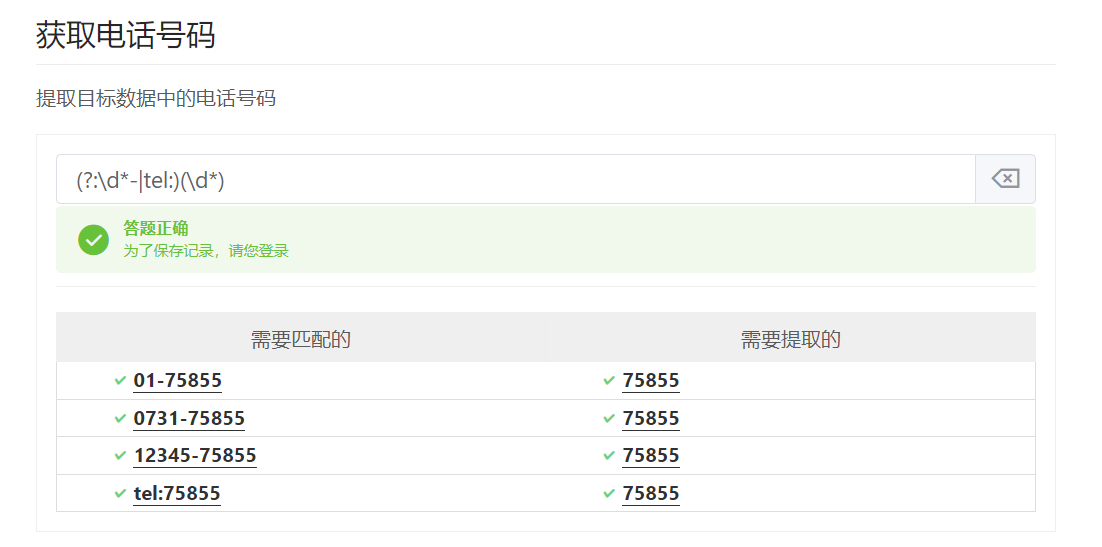
7.分组使用技巧
(\d{4})[-\s./]?(\d{1,2})[-\s./]?(\d{1,2})
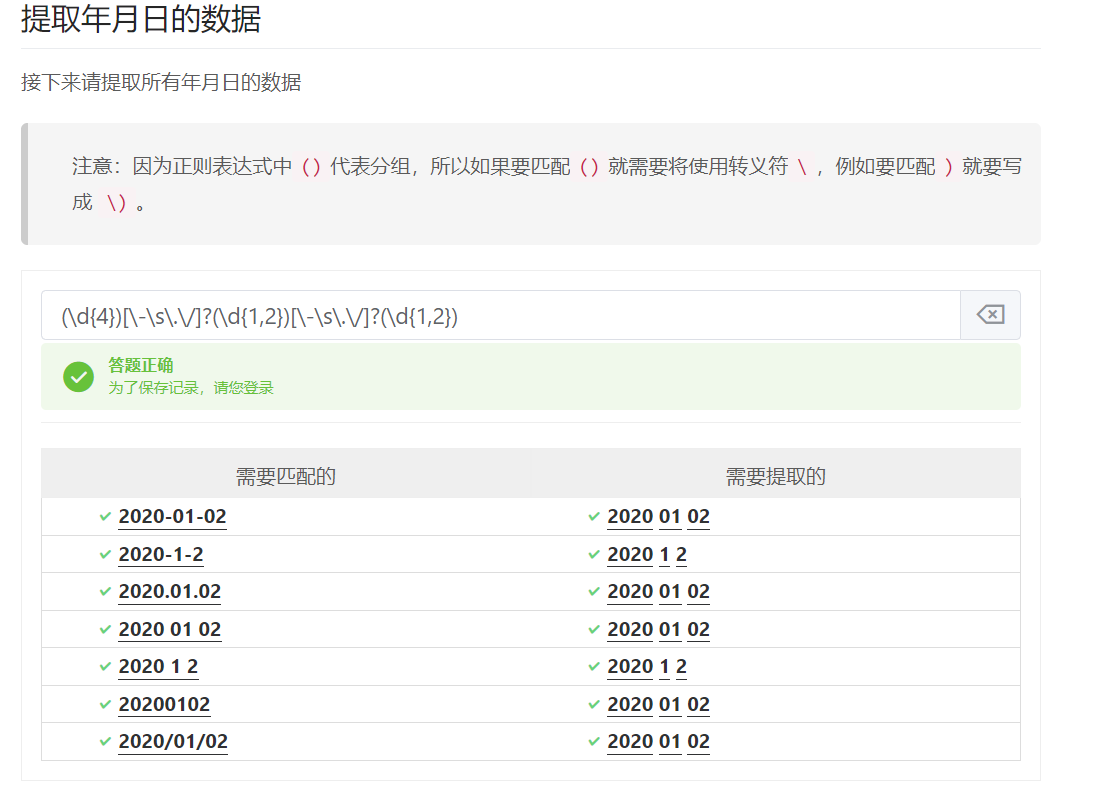
8.提取所有电话号码
(\d{3})[).-]?(\d{3})[.-]?(\d{4})
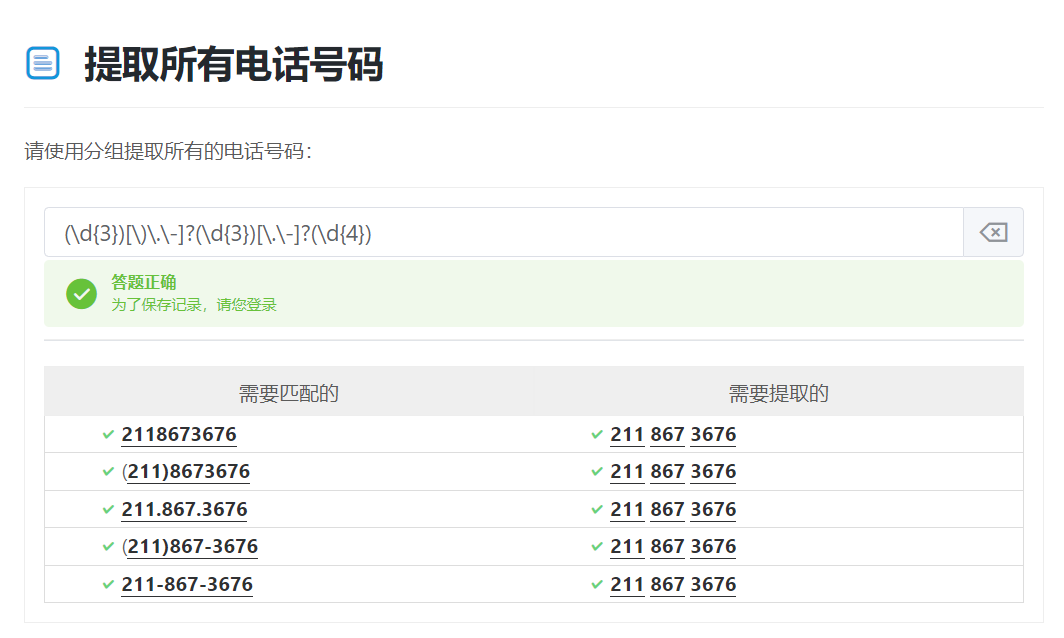
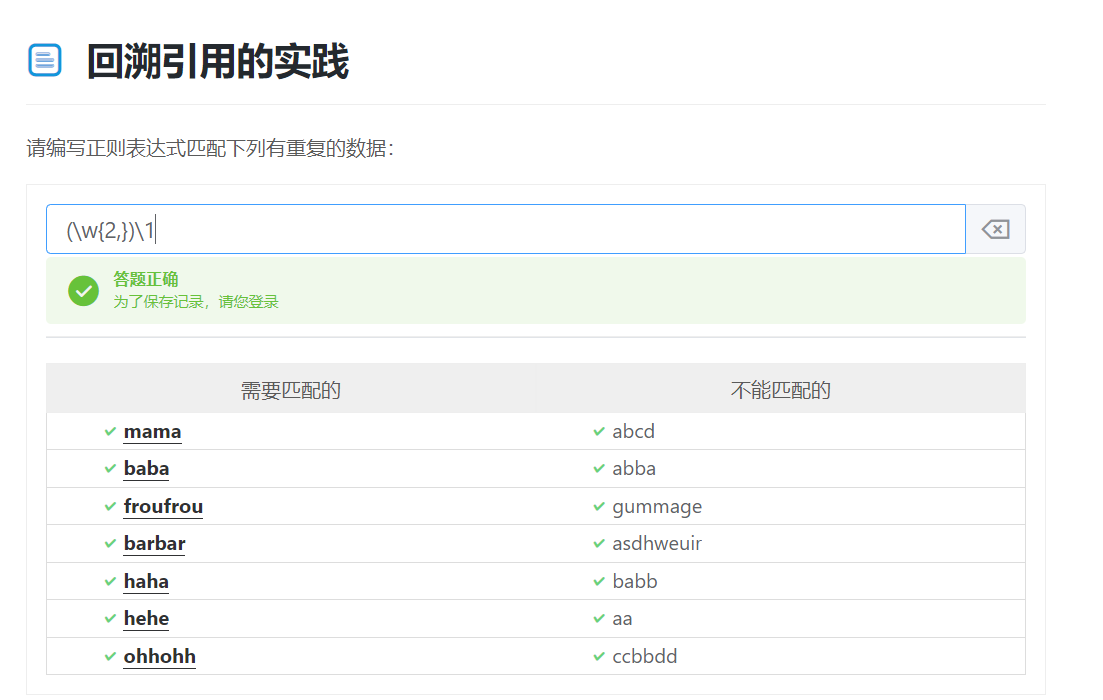
9.分组的回溯引用
正则表达式还提供了一种引用之前匹配分组的机制,有些时候,我们或许会寻找到一个子匹配,该匹配接下来会再次出现。
例如,要匹配一段 HTML 代码,比如:0123<font>提示</font>abcd,可能会编写出这样一段正则表达式:

这确实可以匹配,不过可能还有另一种情况,如果数据改成这样:<font>提示</bar>

在这里font 和 bar 明显不是一对正确的标签,但是我们编写的正则表达式还是将它们给匹配了,所以这个结果是错误的。
我们想让后面分组的正则也匹配font,但是现在所有形式的都会匹配。
那如果想让后面分组的正则和第一个分组的正则匹配同样的数据该如何做呢?
可以使用分组的回溯引用,使用\N可以引用编号为N的分组,因此上述例子的代码我们可以改为:
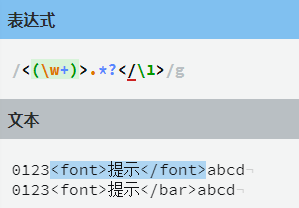
通过这个例子,可以发现 \1 表示的就是第一个分组,在这里第一个分组匹配的是 font 所以\1 就代表font。
练习:
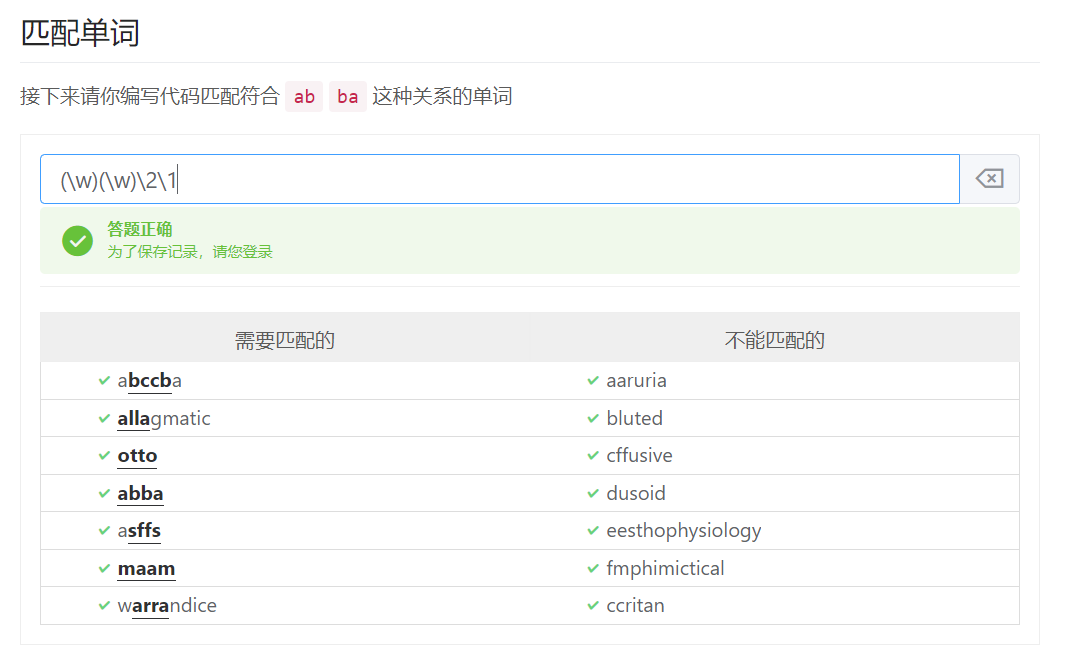
2、先行断言
很多人也称先行断言和后行断言为环视,也有人叫预搜索,其实叫什么无所谓,重要的是知道如何使用它们!
先行断言和后行断言总共有四种:
- 正向先行断言
- 反向先行断言
- 正向后行断言
- 反向后行断言
1.正向先行断言
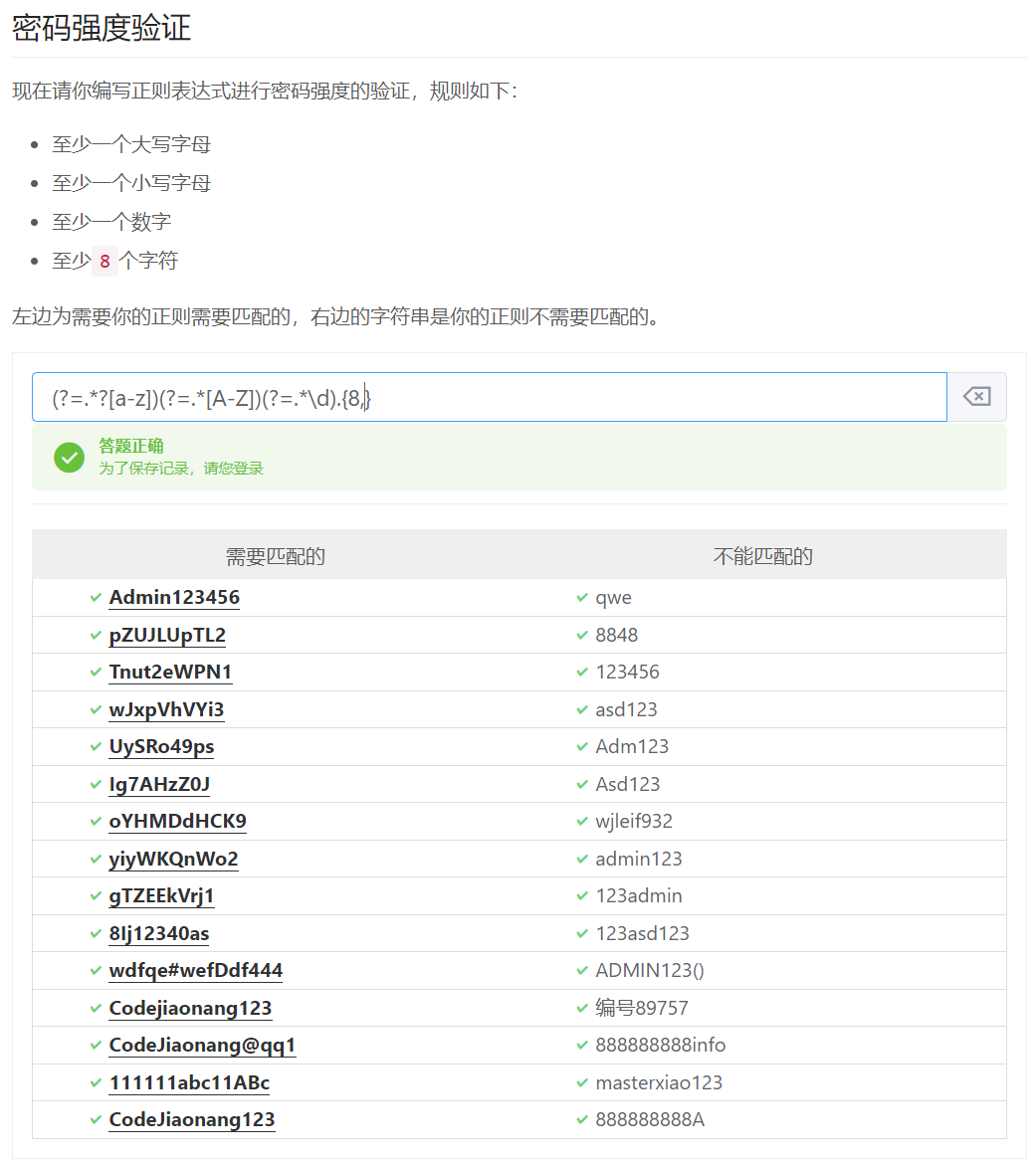
正向先行断言:(?=表达式),指在某个位置向右看,表示所在位置右侧必须能匹配表达式
(?=.?[a-z])(?=.[A-Z])(?=.*\d).{8,}
2.反向先行断言
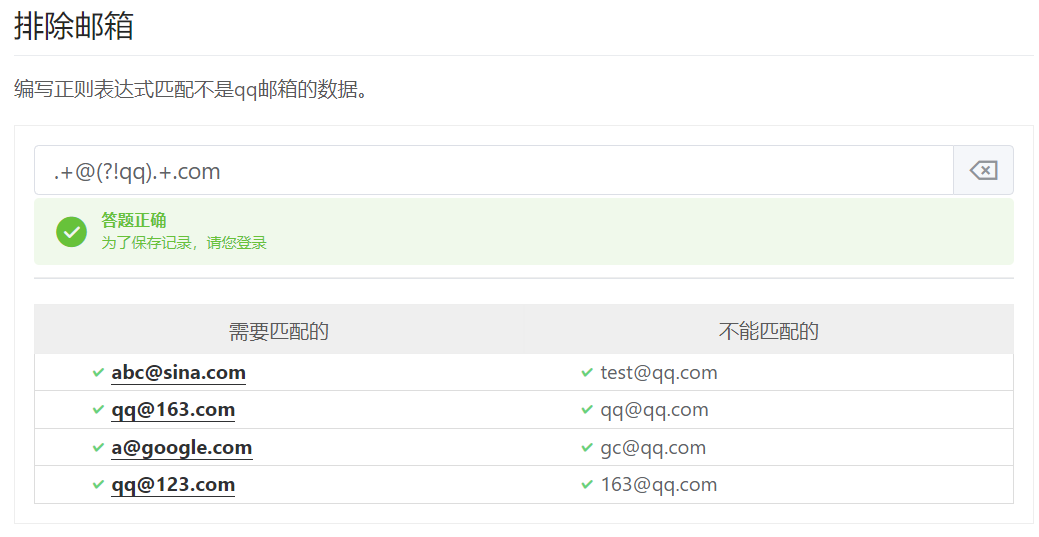
反向先行断言(?!表达式)的作用是保证右边不能出现某字符。
.+@(?!qq).+.com
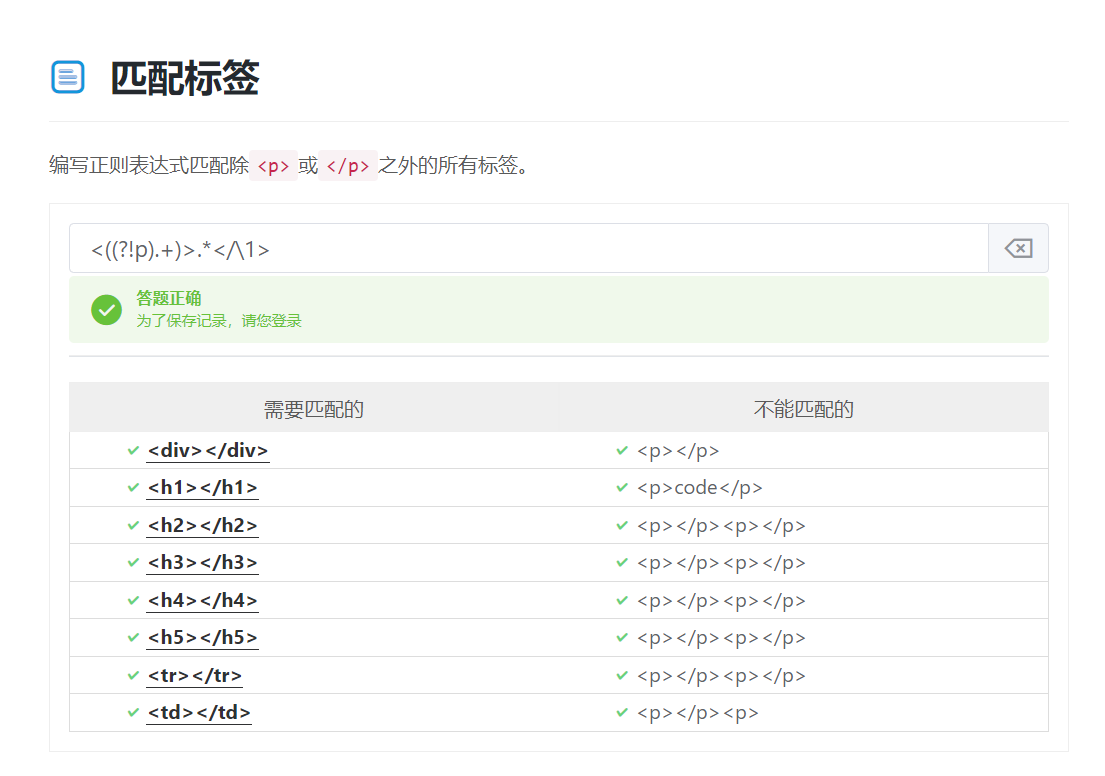
<((?!p).+)>.*</\1>
3、后行断言
本小节只需要你记住一句话:先行断言和后行断言只有一个区别,即先行断言从左往右看,后行断言从右往左看。
1.正向后行断言
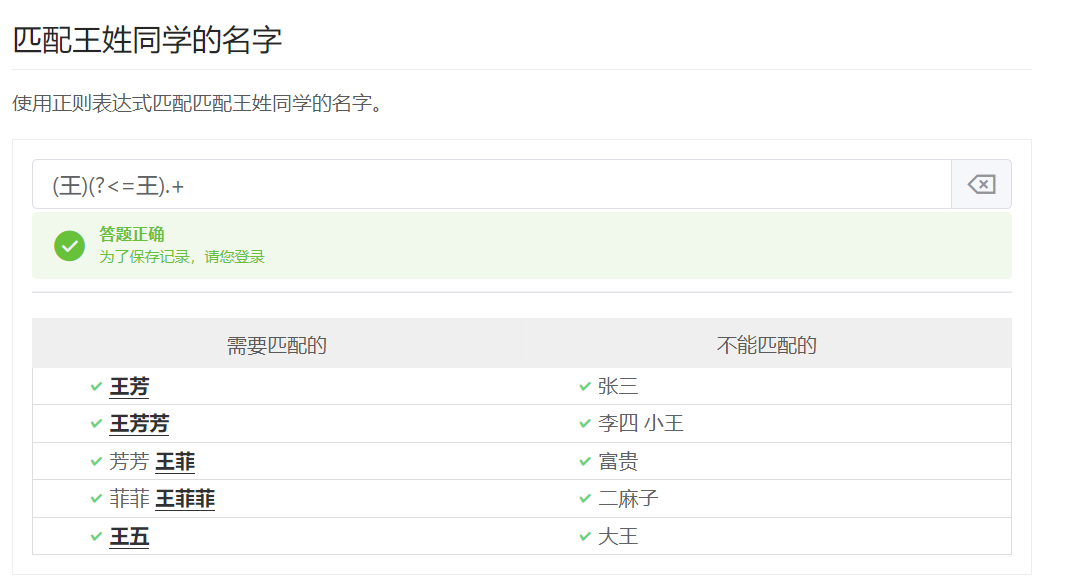
正向后行断言:(?<=表达式),指在某个位置向左看,表示所在位置左侧必须能匹配表达式
(王)(?<=王).+
2.反向后行断言
反向后行断言:(?<!表达式),指在某个位置向左看,表示所在位置左侧不能匹配表达式
^$.*(?<!$)$$
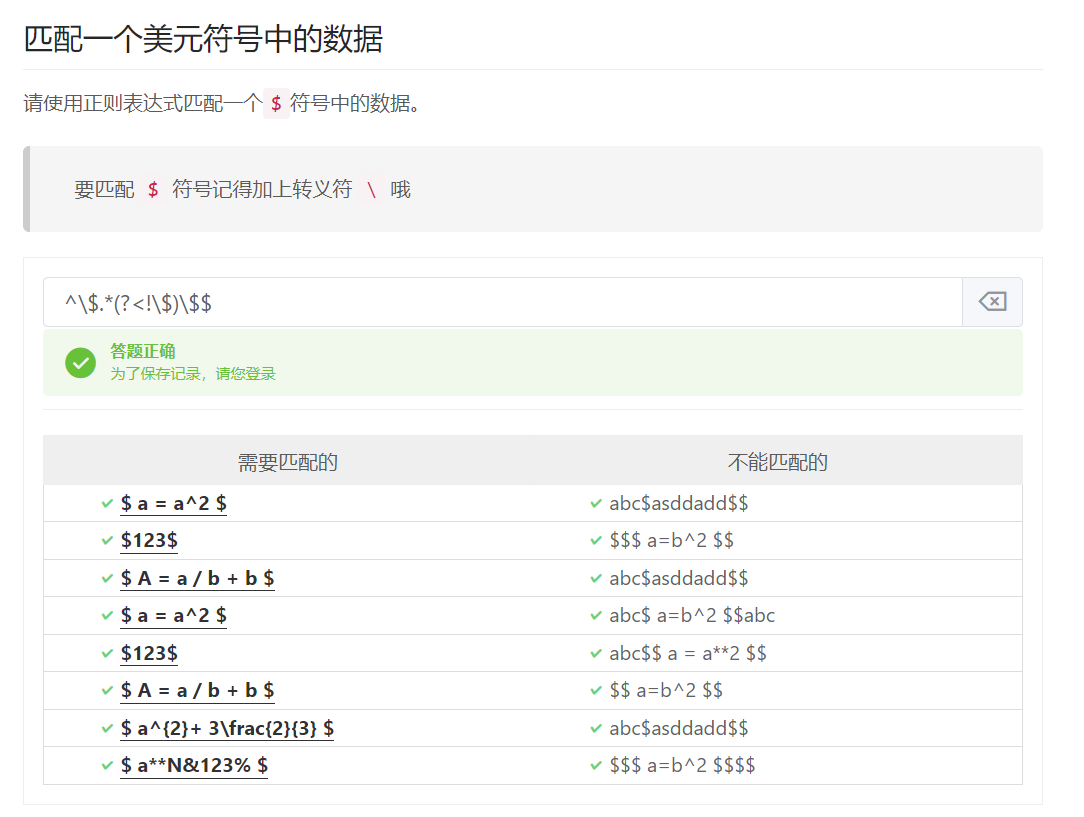
(?<!\$)\$\$[^\$].*\$\$
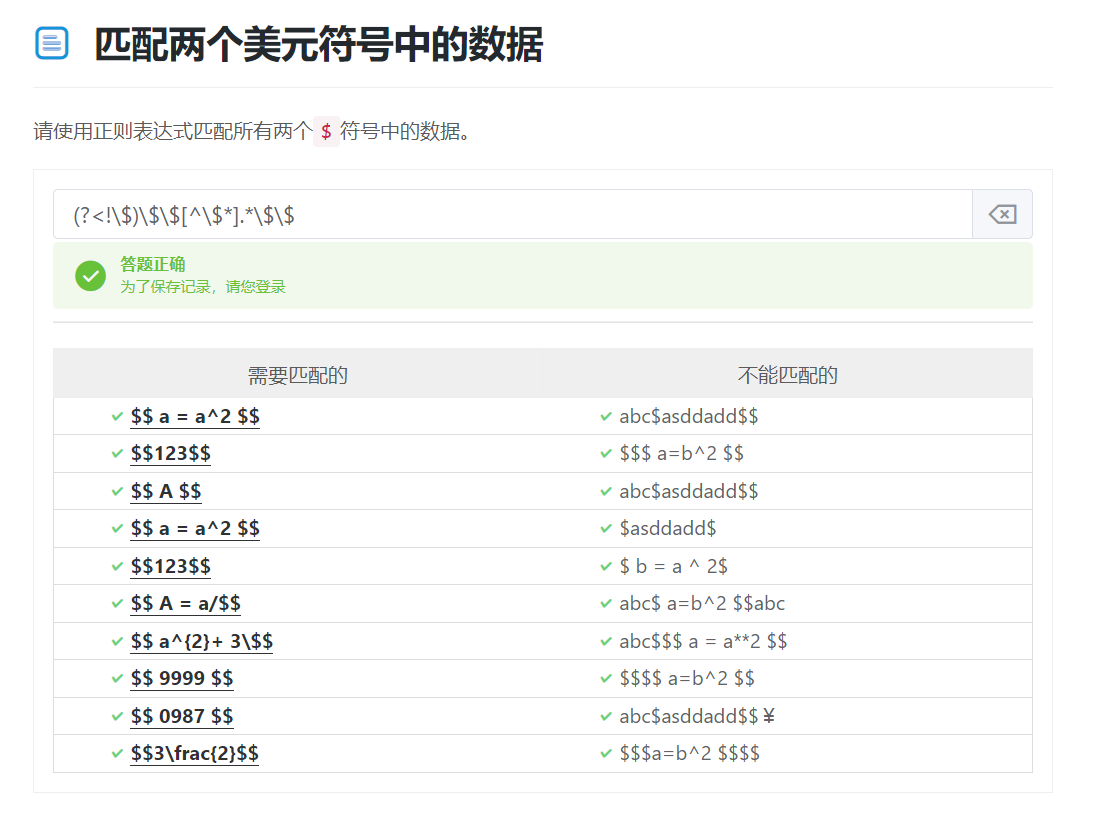
4、总结与实践
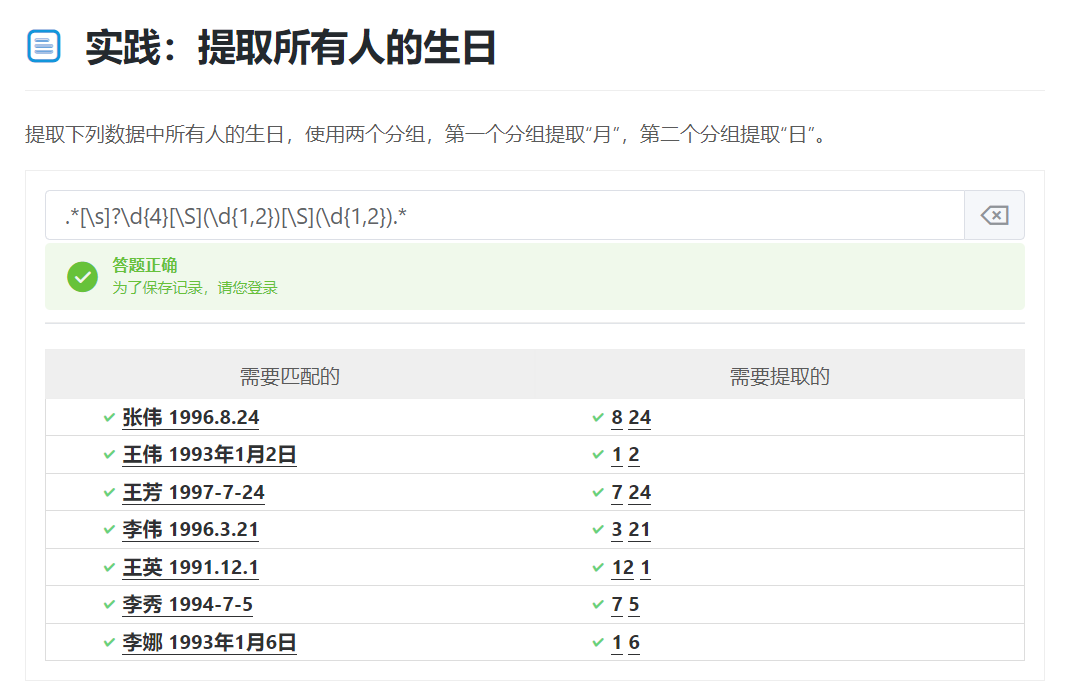
1.提取所有人的生日
.*[\s]?\d{4}[\S](\d{1,2})[\S](\d{1,2}).*
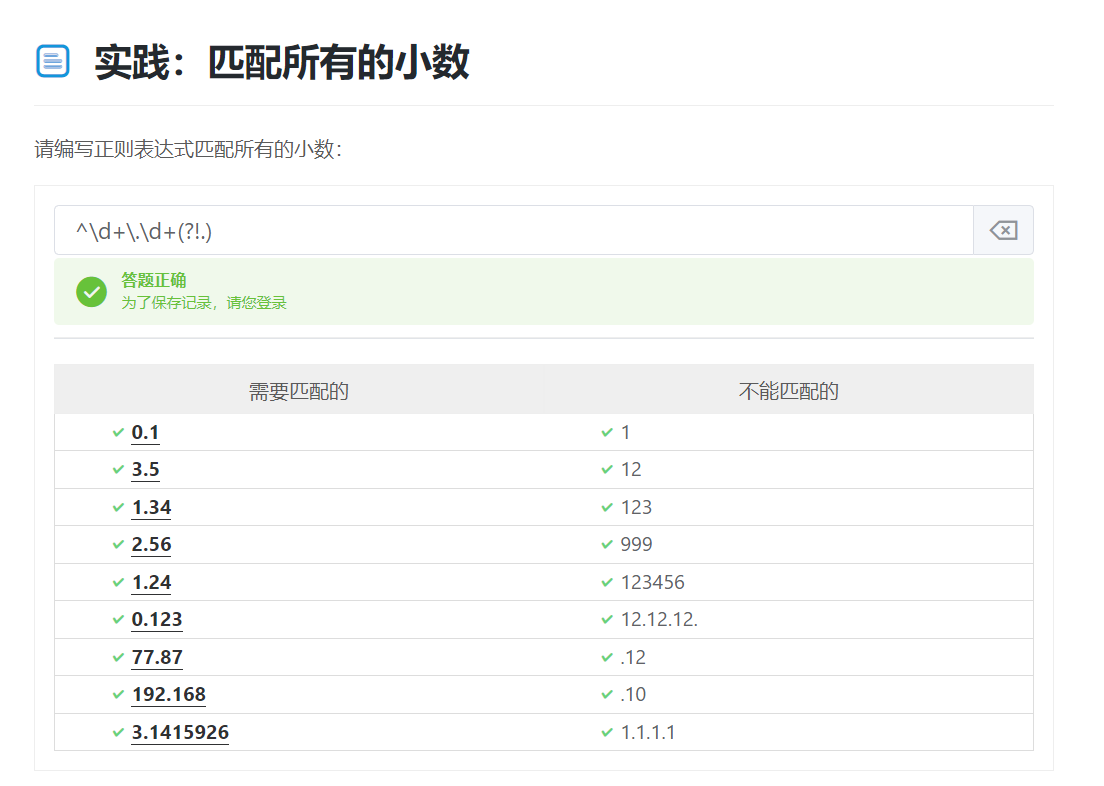
2.匹配所有的小数
^\d+\.\d+(?!.)
后话
那么至此,正则表达式的进阶内容也到此结束了。如果想要巩固自己学习的正则表达式。那么去编程胶囊-正则表达式通关挑战进行最后的试炼吧!
如果你的正则表达式还没有入门,那么可以看我的【python学习】正则表达式入门一文!