Traceback (most recent call last):如果我们从算法角度来考虑C3算法,其实就是把子类的MRO次序基于父类的MRO次序进行merge,并且在每次迭代的过程中,测试是否存在逆序的情况
其中merge方法定义为:
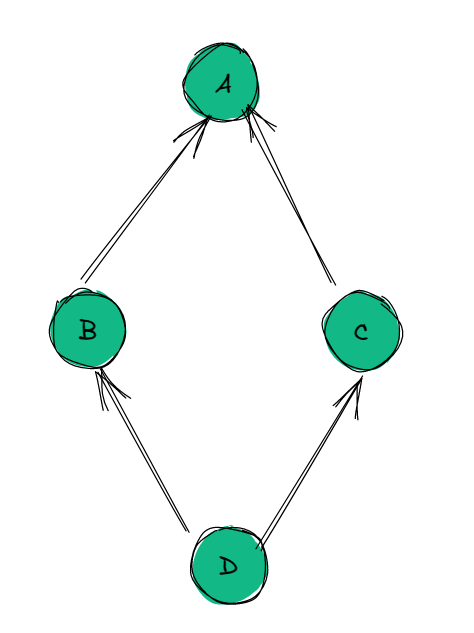
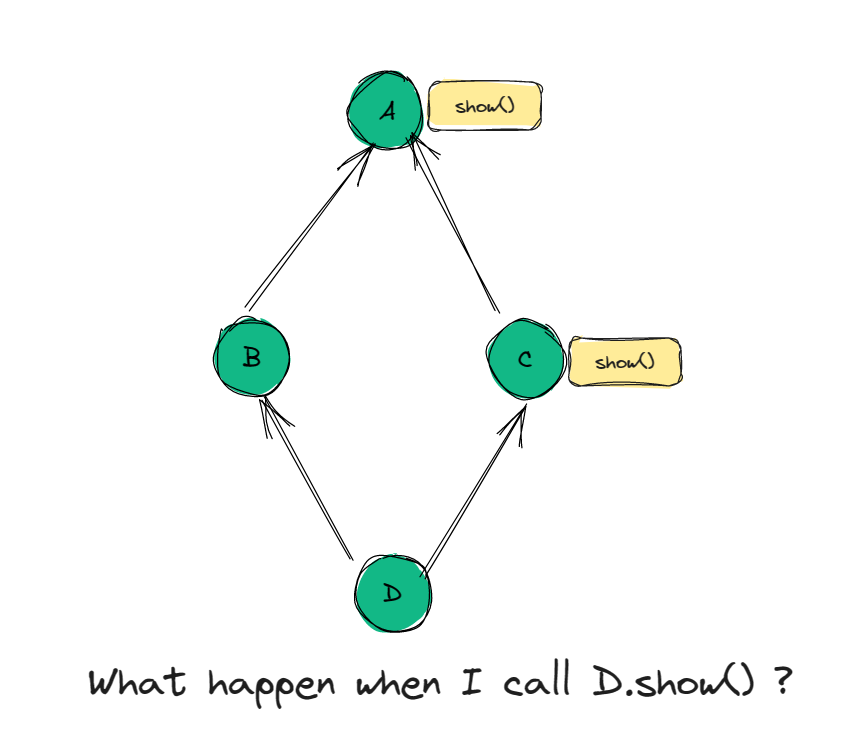
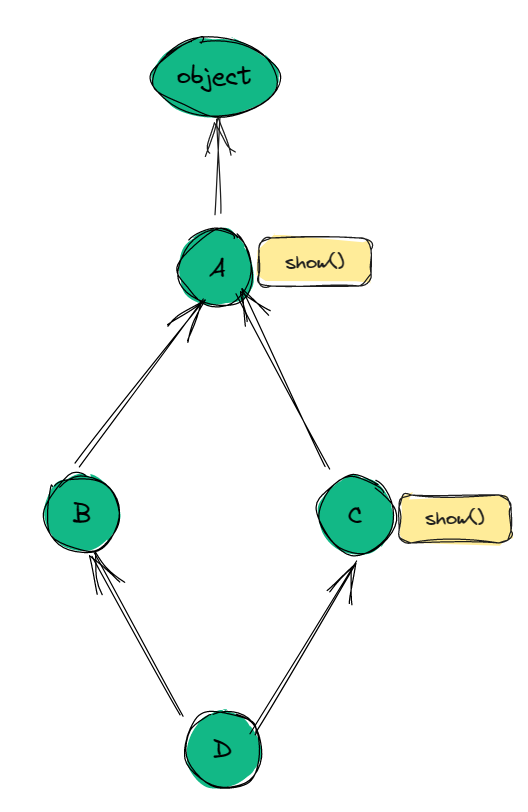
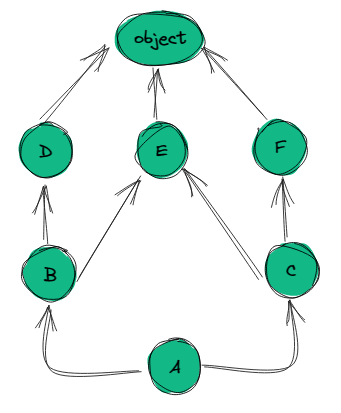
我们来看不同的继承关系的C3算法的流程:
Graph C3 Code mro(D) = [D,O] mro(B) = [B, O]
所以在Python3中,就是使用C3算法来进行MRO搜索的,确保了二义性的多继承不会出现!
super的细节 super只能在新式类中使用!
在一个class中,可以使用super()来获取到这个类在mro列表中的下一个类
那你可能就会说了,super肯定是调用父类的属性或者方法!
但是,这是错误的!
举一个例子!
class A :
def f1 ( self ):
print ( "A f1" )
super () . f1 ()
class B :
def f1 ( self ):
print ( "B f1" )
class C ( A , B ):
pass
C () . f1 ()
上述的代码会打印什么呢?答案是:
明明A和B没有继承关系,为什么A中的super().f1()会执行B中的f1呢?
其实是因为super看的是最初对象的mro列表
C的mro是,[<class '__main__.C'>, <class '__main__.A'>, <class '__main__.B'>, <class 'object'>]
所以在A中的super()获取到的是mro列表中<class '__main__.A'>的下一个,也就是 <class '__main__.B'>
Duck Typing duck typing就是我们常说的鸭子类型
在Python中,如果某个类实现了一些特定的方法,但是没有显式继承某个类,这个类也可以是某些类的子类!
from collections . abc import Iterable
class MyIter :
def __iter__ ( self ):
pass
print ( issubclass (MyIter, Iterable)) # True
虽然这个MyIter没有明确写上继承自Iterable,但是通过issubclass的信息可以知道,MyIter就是Iterable的一个子类
这就是鸭子类型,如果一个东西,它长得像鸭子,叫声像鸭子,走路像鸭子,那么它就是鸭子!
而鸭子类型的实现,可以通过__subclasshook__这个魔术方法来实现!
我们来看看Iterable的源码:
class Iterable ( metaclass = ABCMeta ):
__slots__ = ()
@abstractmethod
def __iter__ ( self ):
while False :
yield None
@ classmethod
def __subclasshook__ ( cls , C ):
if cls is Iterable:
return _check_methods (C, "__iter__" )
return NotImplemented
Iterable定义自己的元类是ABCMeta,有关元类的知识点之后再讨论。 Iterable定义了一个abstractmethod,这个抽象方法装饰器的作用就是,如果一个类显式继承Iterable,那么这个类一定要有一个__iter__的方法,否则会报错 Iterable定义了一个classmethod叫作__subclasshook__,这个方法在调用issubclass()函数的时候会被调用,检测C这个是否含有__iter__这方法,如果有,就返回True,那么在调用issubclass和isinstance的时候就会返回True,证明是子类 说到了这里,其实Python中很多类型都实现了__subclasshook__这个方法,例如上面提到的可迭代对象Iterable,还有迭代器Iterator,还有生成器Generator,都是通过判断某个类中是否存在某些函数来判断是否是子类。
其实可以自己编写一个demo:
from abc import ABC
class MyBaseClass ( ABC ):
@ classmethod
def __subclasshook__ ( cls , subclass ):
print ( cls )
print (subclass)
return hasattr (subclass, 'my_method' ) and callable (subclass . my_method)
class MySubClass :
def my_method ( self ):
print ( "Hello, World!" )
print ( issubclass (MySubClass, MyBaseClass)) # True
print ( isinstance ( MySubClass (), MyBaseClass)) # True
抽象基类 如果不想使用Duck Typing的方式来实现多态,可以使用抽象基类的方式来规范父子类标准。
从一个小demo看起:
from abc import ABC , abstractmethod
class MyBaseClass ( ABC ):
@abstractmethod
def need_this_func ( self ):
pass
@ classmethod
def __subclasshook__ ( cls , subclass ):
print ( cls )
print (subclass)
return hasattr (subclass, 'my_method' ) and callable (subclass . my_method)
class MySubClass ( MyBaseClass ):
def my_method ( self ):
print ( "Hello, World!" )
MySubClass ()
'''
Traceback (most recent call last):
File "e:/myworks/vscode_workspace/python_workspace/python_learning/class_learning.py", line 88, in <module>
MySubClass()
TypeError: Can't instantiate abstract class MySubClass with abstract methods need_this_func
'''
上述代码实现了一个抽象基类MyBaseClass,因为这个类继承了abc.ABC,而abc.ABC的元类是abc.ABCMeta,这个元类规范了使用了abstractmethod修饰的函数一定要在子类中实现,否则报错
所以在我们自己写的MySubClass中,显式继承了MyBaseClass,如果没有实现need_this_func,那么就会报错!
使用抽象基类的方式可以更好的规范我们的父子类代码!
类方法与静态方法 类方法在class中可以使用装饰器@classmethod来修饰,第一个参数是cls,表示当前这个类
class X :
@ classmethod
def instance ( cls ):
if hasattr ( cls , "_obj" ):
return cls . _obj
cls . _obj = X ()
return cls . _obj
print (X . instance ())
print ( dir (X))
'''
<__main__.X object at 0x000001EB271CFD30>
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_obj', 'instance']
'''
这里就用类方法类生成了一个实例,同时这也是单例模式的一种写法
静态方法可以看作类方法少了cls这个参数,就相当于是绑定到一个类上的一个方法,不需要生成实例就可以调用的方法
class Util :
@ staticmethod
def date ():
return "20230531"
print (Util . date ()) # "20230531"
metaclass翻译成中文,就是元类
我们都知道,在Python中,万物皆对象,但是,思考一个问题——对象是由类创建的,那么类是由什么创建的呢?
答案是,类是由其元类创建的,同时元类也是一种类
type元类 在Python的基础类型中,所有基础类的元类是type
你可能会疑惑了,type不是用来查看某个对象的类的吗?
但是type的用法远远不止这一条!
我们先来证明一下基本类型都是由元类构建的,看如下的代码输出!
print ( type ( str ( 1 )))
print ( type ( str ))
print ( type ( int ( "1" )))
print ( type ( int ))
print ( type ( list ( "123" )))
print ( type ( list ))
print ( type ( tuple ( "123" )))
print ( type ( tuple ))
'''
<class 'str'>
<class 'type'>
<class 'int'>
<class 'type'>
<class 'list'>
<class 'type'>
<class 'tuple'>
<class 'type'>
'''
发现了没有:
所有由基本类型构建的对象执行type()后,都指向这个类 基本类型的type()执行后,返回的都是<class 'type'> 这个<class 'type'>其实就是metaclass,也就是元类 来解释一下相关概念:
元类:实例化产生类的类 元类 --> 元类.实例化() --> 类 --> 类.实例化() --> 对象 既然我们知道了基本的数据类型都是由type这个类构建而来的,那么我们可以不使用class这种关键字创建出一个类吗?
答案是——肯定可以!
我们就使用最基本的metaclass——type,来实现无class关键字构造一个类
class_name = "Wood" # 类名
class_bases = ( object , ) # 基类
class_dic = {}
class_body = '''
def __init__(self):
pass
def info(self):
print("test info")
'''
exec (class_body, {}, class_dic) # 使用exec将class_body中的内容装入class_dic中
Wood = type (class_name, class_bases, class_dic)
obj = Wood ()
obj . info ()
print ( dir (obj))
print ( type (obj))
'''
test info
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'info']
<class '__main__.Wood'>
'''
上述代码的输出结果已经告诉我们了,这个Wood类已经被创建了,并且是使用type的方式构建的!
我们可以根据上述的代码思考一些问题:
class关键字到底做了什么来构建了一个class? 元类充当了什么样的一个角色? 其实第一个问题思考一下就可以得出简单的答案:
获取类名 获取基类(父类) 获取名称空间 调用元类构建这个类 第二个问题在刚开始就说了:
自定义元类 先看一个demo,继承了type的元类
class MyMetaclass ( type ):
def __init__ ( self , * args , ** kwargs ):
print (args)
print (kwargs)
print ( self )
print ( self . mro ())
print ( dir ( self ))
class X ( metaclass = MyMetaclass ):
def func1 ( self ):
pass
X ()
'''
('X', (), {'__module__': '__main__', '__qualname__': 'X', 'func1': <function X.func1 at 0x000001D969F9C1F0>})
{}
<class '__main__.X'>
[<class '__main__.X'>, <class 'object'>]
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'func1']
'''
可以看到输出,args中有三个参数:
类名 基类(父类) 命名空间 所以可以看到,在元类的__init__参数中,传入了需要被构造的类的必要属性
那么我们可以在元类中执行什么样的操作呢?同时又有如下几个疑点:
如果仅仅是在__init__中注入一些属性,那么如何解释传入的参数中不存在object,但是self.mro()中又有object了? Python3中都是新生类,如何保证class申明后不显式继承object也会自动继承object? 有什么方法是在__init__之前就执行的? 我们一个一个来解答,首先来了解一个类的构建过程。
__new__ 我们一般会把一个class的__init__函数当作构造函数。
但是,其实真正创建一个类的函数是__new__
我们来看一个例子,证明__new__在__init__之前执行
class MyMetaclass ( type ):
def __init__ ( self , * args , ** kwargs ):
print ( "-" * 50 )
print (args)
print (kwargs)
print ( self )
print ( self . mro ())
print ( dir ( self ))
def __new__ ( cls , * args , ** kwargs ):
print ( cls )
print (args)
print (kwargs)
return super () . __new__ ( cls , * args, ** kwargs)
class X ( metaclass = MyMetaclass ):
def func1 ( self ):
pass
x = X ()
我们直到metaclass构建一个类的流程,由metaclass创造一个类对象,上述代码中这个类对象就是X,再由X创造一个类对象,这个就是上述代码中的x
那么上述代码的输出是什么呢?
< class '__main__.MyMetaclass' >
( 'X', (), { '__module__' : '__main__' , '__qualname__' : 'X' , 'func1' : < function X.func1 at 0x0000013C3A89C 280 > })
{ }
--------------------------------------------------
( 'X', (), { '__module__' : '__main__' , '__qualname__' : 'X' , 'func1' : < function X.func1 at 0x0000013C3A89C 280 > })
{ }
< class '__main__.X' >
[ < class '__main__.X' > , < class 'object' > ]
[ '__class__' , '__delattr__' , '__dict__' , '__dir__' , '__doc__' , '__eq__' , '__format__' , '__ge__' , '__getattribute__' , '__gt__' , '__hash__' , '__init__' , '__init_subclass__' , '__le__' , '__lt__' , '__module__' , '__ne__' , '__new__' , '__reduce__' , '__reduce_ex__' , '__repr__' , '__setattr__' , '__sizeof__' , '__str__' , '__subclasshook__' , '__weakref__' , 'func1' ]
可以看到,__new__的输出早于__init__,所以我们的结论被证实了。
每个class,都是由__new__构造出来的 __new__早于__init__那么在哪个地方会让metaclass去调用__new__再去调用__init__,最终再去构造一个基本类呢?
有一个魔术方法叫作__call__,就是一个类的对象在被调用的时候会执行的 __call__ 如果在一个类中,指定了__call__方法,那么这个类的实例化对象也可以加上()被调用
class TestClass :
def __init__ ( self , name ) -> None :
self . name = name
def __call__ ( self , * args , ** kwds ):
print ( self . name)
obj = TestClass ( "woodwhale" )
obj () # woodwhale
上述代码中实例化的对象obj,如果被当作函数执行,就会触发__call__函数,从而执行print(self.name)这条语句
__call__函数是可以有返回值的,当作一个函数就好理解了__call__函数还可以有参数,这点也和函数一样还记得如何使用type来构造一个class吗
class_name = "TestClass"
class_bases = ( object , )
class_dic = {}
class_body = '''
def __init__(self):
pass
def info(self):
print("test info")
'''
exec (class_body, {}, class_dic)
TestClass = type (class_name, class_bases, class_dic)
既然type是一个类,那么在调用type()的时候,其实触发的就是type这个类的__call__方法 也就是说,在执行type(class_name, class_bases, class_dic)的时候,其实是在__call__函数中返回了一个类对象 让我们思考一个问题,一个最简单的类,它的__init__函数,为什么一定会被调用?
其实就是因为最基本的类的元类是type,而在type的__call__函数中,会调用这个最基本类的__new__和__init__ 那么如果我们编写一个MyType继承自type,同时在这个MyType的__call__中动手脚,是不是可以控制一个类的产生?
class MyMetaclass ( type ):
def __call__ ( self , * args , ** kwds ):
print ( self )
print ( "__call__" )
return "woodwhale"
class X ( metaclass = MyMetaclass ):
def func1 ( self ):
pass
print ( X ())
'''
<class '__main__.X'>
__call__
woodwhale
'''
可以看到,这里X()的返回值是woodwhale,调用链如下:
X()的第一步会去先实例化一个MyMetaclassMyMetaclass的实例化对象是X而X()其实就是MyMetaclass实例化对象被调用了,所以会触发MyMetaclass的__call__函数 在MyMetaclass的__call__中,返回值是woodwhale 所以最后print(X())的结果是woodwhale 这样的调用链就很清晰了!
那么我们可以在__call__中,实例化一个X的对象
class MyMetaclass ( type ):
def __call__ ( self , * args , ** kwargs ):
print ( self )
print ( "__call__" )
x_obj = self . __new__ ( self )
self . __init__ ( self , * args, ** kwargs)
return x_obj
class X ( metaclass = MyMetaclass ):
def __new__ ( cls , * args , ** kwargs ):
# return object.__new__(cls)
obj = super () . __new__ ( cls )
# 随意操作!
return obj
def __init__ ( self , name ) -> None :
print ( "__init__" )
self . name = name
def func1 ( self ):
pass
x = X ( "123" )
print (x . name)
所以,如果我们想给一些类做定制化处理,可以在metaclass的__call__函数中处理
属性查找 在通常的认知中,类与对象的属性查找的链子是:
对象 --> 类 --> 父类 --> object 找不到就报错 但是,在了解了metaclass这样的存在之后,其实查找链就有两种情况:
对于对象 对于类 对于对象的查找顺序,其实还是我们认知中的链子:
对象 --> 类 --> 父类 --> object 找不到就报错 但是,对于类,就不同了,多了一个查找元类的链子:
对象 --> 类 --> 父类 --> object --> 自定义的metaclass --> type 找不到就报错 After All 上述内容仅仅针对Python代码层面的类,并没有分析CPython这种更深层次的源码分析,未来有时间一定看源码!